






Google’s AI Overview cited three sources for a query we ranked #3 for. Our article wasn’t one of them. The site that got cited ranked #47 in traditional organic results. That gap, between where Google surfaces content in AI Overviews versus where it ranks pages in the ten blue links, is the operating reality of search in 2026.
The ranking system you’re optimizing for has split into two distinct mechanisms. One still uses backlinks and domain authority to organize web pages. The other extracts entity relationships and attributes from those pages to answer questions directly. Your content can win in one system and disappear in the other. Most teams are still optimizing for the wrong one.
ℹ️ Google has not fully documented how AI Overviews select citations. The mechanisms described here reflect observable patterns across multiple queries, industries, and publisher case studies rather than official ranking disclosures.
The Extraction Layer Runs First
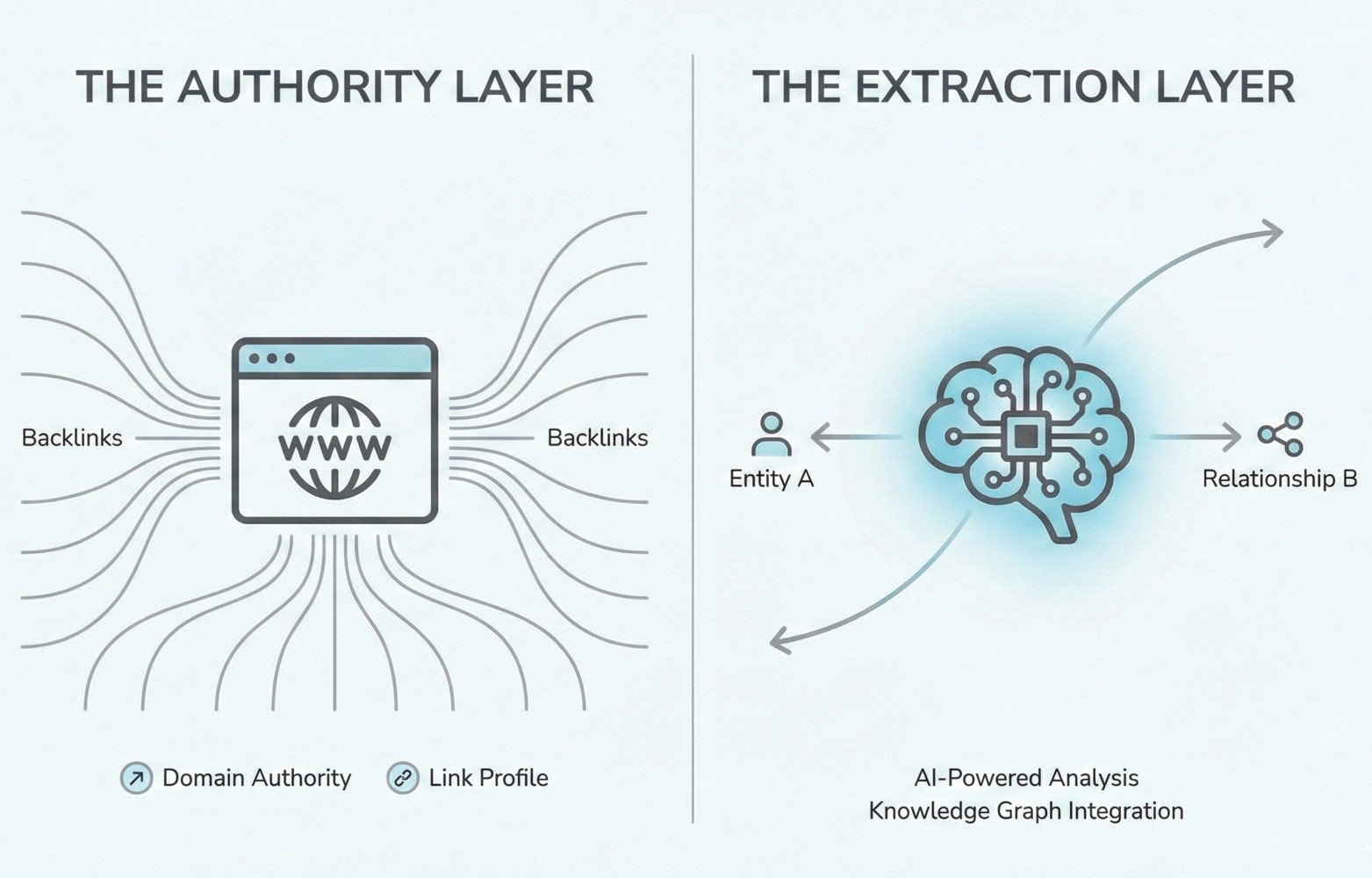
Google’s ranking system now prioritizes entity extraction over traditional on-page signals. Before evaluating backlinks or domain authority, the system parses content to identify entities, their attributes, and relationships. Content that fails entity extraction gets deprioritized regardless of traditional SEO strength.
When Gemini processes a search query, it doesn’t scan your page for keyword density or H2 tags. It checks whether your content maps to entities in Google’s Knowledge Graph. If the entities are missing or ambiguous, your content gets filtered out before backlink analysis even runs.
This is why pages with weak link profiles but clear entity signals outrank authoritative domains in AI Overviews. The system values structural clarity over historical authority. A site with 15 backlinks that explicitly states, for example: “Dr. Jane Ann Smith, Chief of Cardiology at Stanford Medical Center” will outperform a site with 1,500 backlinks that says “leading expert in the field.”
The problem is that most SEO content is written to satisfy keyword targets, not entity extraction. You optimized for “best project management software” but never explicitly connected Asana, Monday.com, and ClickUp to their parent companies, founding dates, or primary use cases. The content reads fine to humans. To an entity parser, it’s structurally incoherent.
What No Longer Predicts Visibility
Traditional SEO metrics — keyword placement, internal linking, domain authority — have diminishing predictive power for AI-mediated search visibility. Pages that rank well in traditional organic results often fail to appear in AI Overviews because they lack explicit entity signals and attribute statements.
Keyword optimization still affects traditional organic rankings and helps with query disambiguation, but it plays a diminishing role in AI Overview extraction. Gemini doesn’t count keyword mentions. It looks for statements that assert entity attributes: “X is a Y that does Z.” If your content implies relationships instead of stating them, the extraction layer skips it.
Internal linking used to distribute authority and help crawlers discover content. That still matters for indexing. But linking from your “About” page to your “Services” page doesn’t create entity relationships in the Knowledge Graph. The system needs explicit schema markup or declarative statements to connect those entities.
Domain authority determines whether you rank on page one. It doesn’t determine whether Gemini cites you when answering a question. The two mechanisms evaluate different signals. You can have a DR 70 site that gets zero AI Overview citations because your content doesn’t state entity attributes clearly enough to extract.
The biggest failure point is author attribution. Most sites still use bylines like “Posted by Marketing Team” or “Written by Staff.” Gemini treats that as an anonymous source. If you want E-E-A-T credit, you need full author entity declarations: name, role, credentials, institutional affiliation. Anything less gets classified as unattributed content.
The Entity-First Content Model
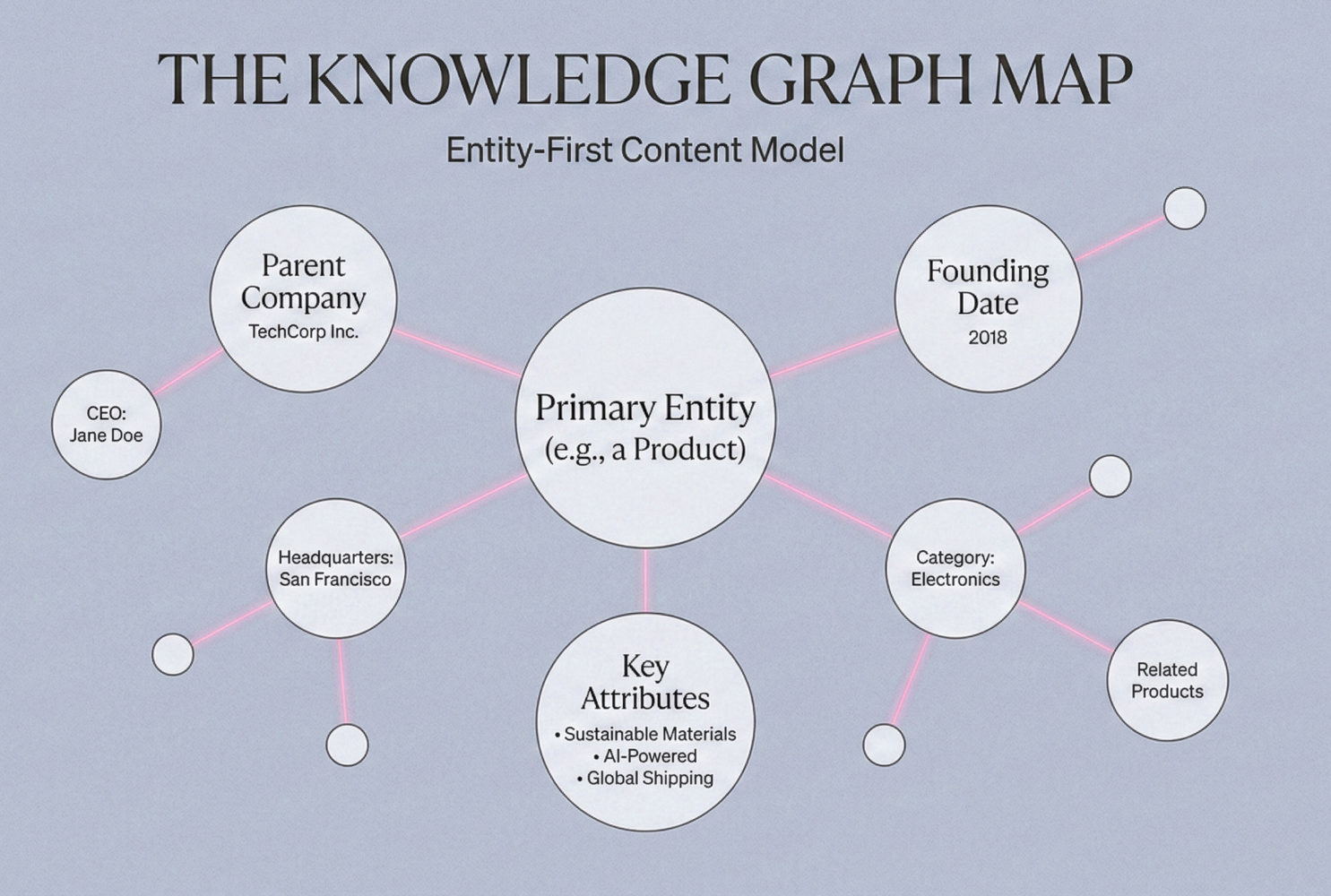
Entity-first content explicitly declares what entities are, what they do, and how they relate to other entities,using structured statements rather than implied context. This approach optimizes for machine extraction before human readability, reversing traditional content strategy priorities.
Start by identifying the primary entity on each page. If you’re writing about a product, state the product name, company, category, and primary function in the first 100 words. Don’t assume the reader or the system already knows. Explicit declaration beats contextual inference every time.
Next, map the secondary entities. If you mention a competitor, state what they are: “Competitor X, a cloud-based project management platform founded in 2011, offers similar functionality.” That single sentence creates three extractable attributes: category, founding date, feature set. Compare that to “Competitor X also offers these features”, which creates zero.
Use schema markup for structured data, but don’t rely on it exclusively. Gemini extracts from natural language statements as much as from JSON-LD. The most effective approach combines both: schema for machine parsing, declarative sentences for extraction redundancy. If the schema fails to load or gets misinterpreted, the text-based statements still work.
Author entities need the same treatment. Every article should state: “[Author Name], [Role] at [Organization], has [credentials/experience].” That maps to Person entity with [Job Title], [Works For], and credential attributes. Skip any element and the entity becomes incomplete. Gemini won’t cite incomplete entities in high-stakes queries.
The Three-Statement Pattern
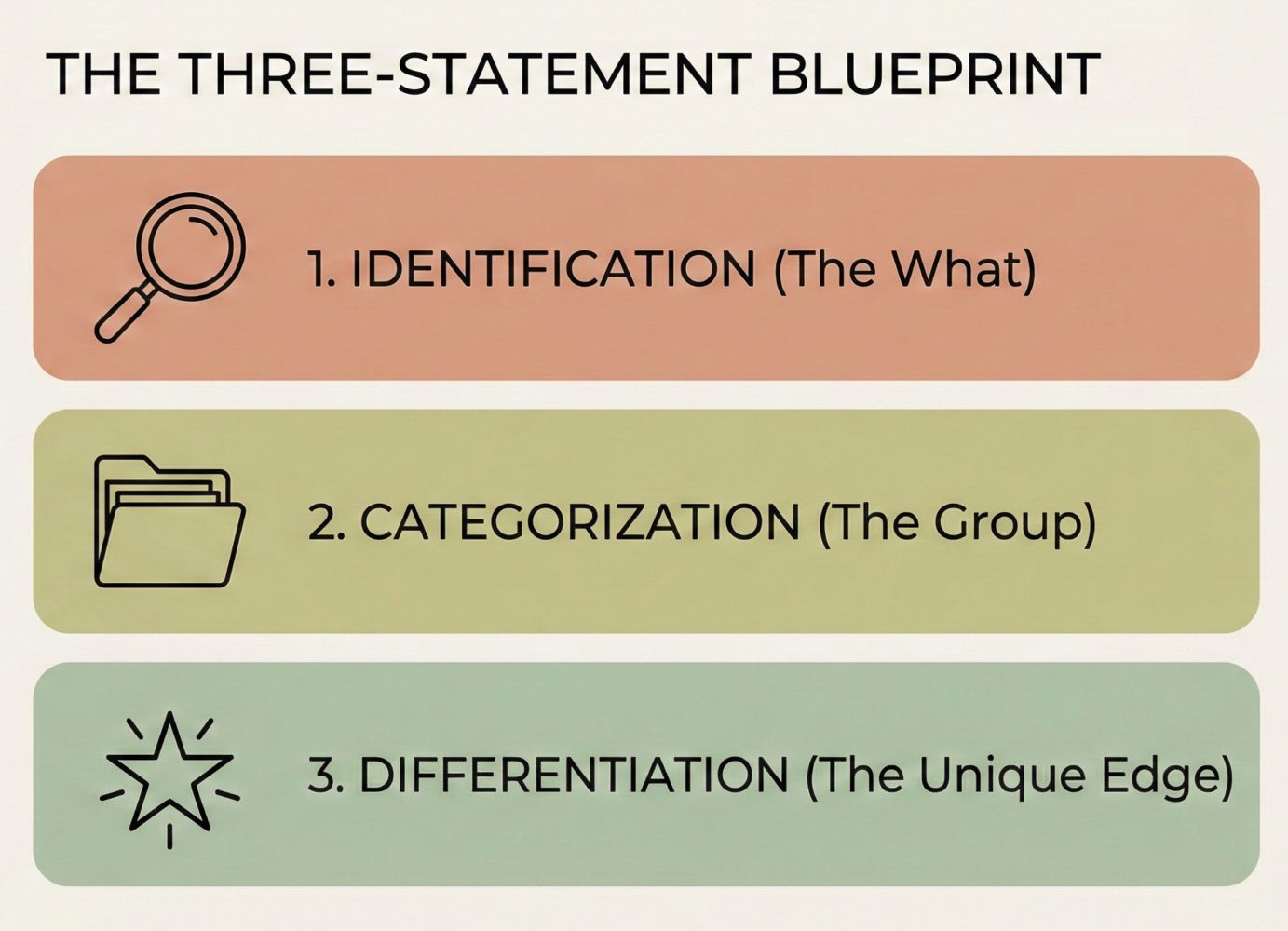
Every entity mention should trigger three statements: identification, categorization, and differentiation. Identification names the entity. Categorization places it in a class. Differentiation explains what makes it distinct from other members of that class.
Example: “Notion is a workspace tool that combines notes, databases, and project management. Unlike specialized tools like Asana or Roam Research, Notion integrates multiple content types in a single interface.” That pattern creates extractable attributes for category membership and competitive positioning. The system can now answer “What is Notion?” and “How does Notion differ from Asana?”
Most content skips differentiation. You’ll see pages that state what something is but not how it differs from alternatives. That works for human readers who bring context. It fails for extraction systems that need explicit contrast. If you don’t state the difference, the system can’t reliably attribute it to you.
The Citation Collapse Problem
AI Overviews cite 2-4 sources per answer instead of directing users to ten blue links. Multiple industry studies and publisher observations indicate substantial traffic compression for queries that trigger Overview responses. Sites that previously captured long-tail traffic through ranking positions 3-10 now receive zero visibility if they’re not in the extracted citation set.
When traditional search returned ten results, you had multiple chances to capture traffic. Ranking #7 still generated clicks. AI Overviews compress that distribution. If you’re not in the top 2-3 extracted sources, you’re invisible. The system doesn’t show “more results” links the way it does in traditional organic.
This changes the volume equation. A page that ranked #5 for 50 long-tail keywords could previously generate 500 clicks per month. If those keywords now trigger AI Overviews and you’re not cited, that traffic disappears. The aggregate effect compounds across your entire content library.
Tracking this shift requires monitoring both traditional rankings and AI citation patterns. The best AI search visibility tools for seo agencies now assess brand presence across ChatGPT, Perplexity, and Google AI Overviews in addition to conventional SERP positions. Emerging platforms such as Peec AI illustrate this shift by analyzing which sources are surfaced in AI-generated responses and how brand mentions evolve as generative search reshapes discovery.
The mitigation strategy is concentration. Instead of covering 50 related topics in separate articles, create a single authoritative resource that establishes you as the primary source for an entity cluster. Be the page that Gemini cites for all related queries instead of competing for individual keyword rankings.
That requires abandoning the traditional hub-and-spoke content model. You can’t just link 20 thin blog posts to a pillar page and expect authority transfer. The extraction layer treats each page independently. If your supporting content doesn’t add unique entity attributes, it dilutes your authority instead of concentrating it.
Schema Markup That Actually Gets Extracted
Generic schema types like Article and Blog Posting provide minimal extraction value in 2026. Effective schema uses specific types: Person, Organization, Product, How To, FAQ Page, with complete attribute sets that match the entity relationships stated in body content.
Article schema tells Google you published something. It doesn’t help with entity extraction. If you’re writing about a software product, use Product schema with manufacturer, releaseDate, category, and aggregateRating. Those attributes map directly to Knowledge Graph fields.
Person schema for authors needs sameAs links to verified profiles — LinkedIn, university directory pages, professional association listings, or Wikidata. Without sameAs, the system can’t confirm entity identity. You could have the world’s leading expert on a topic, but if their Person schema lacks verification links, they’re treated as an unverified source.
Organization schema should connect to Wikidata or Crunchbase entities when possible. That creates bidirectional verification. Google knows your organization exists because external databases reference it. That’s stronger than self-asserted schema with no external validation.
The validation gap is where most implementations fail. You can add perfect schema syntax but if the attributes don’t match what’s stated in your content or what’s recorded in external databases, the system flags it as inconsistent. Consistency across sources matters more than schema completeness.
The Author Authority Rebuild
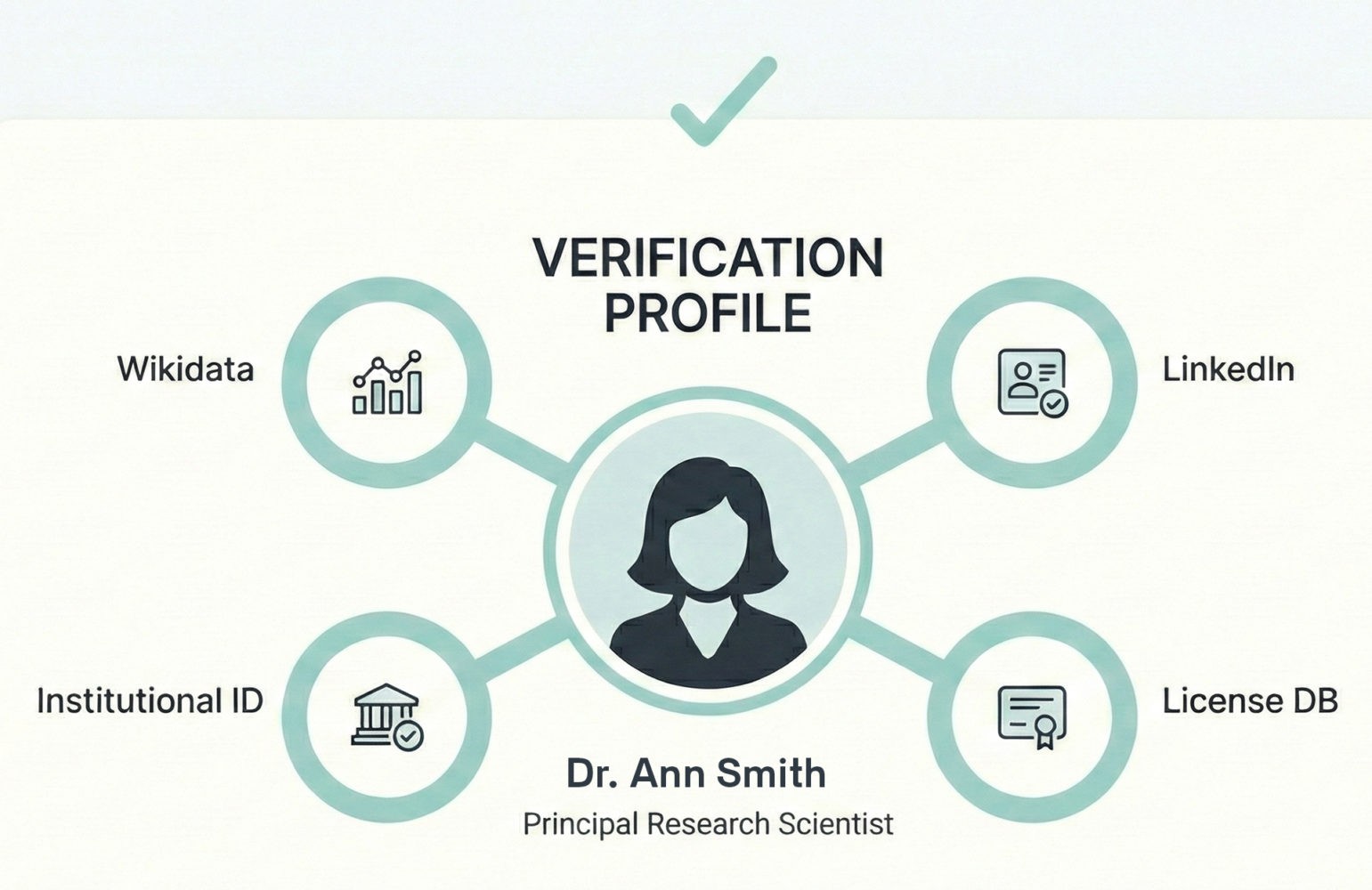
Google’s evaluation of author expertise increasingly depends on verified entity presence across multiple databases rather than on-site credentials alone. Authors without Wikipedia entries, university affiliations, or professional organization profiles typically receive lower authority scores regardless of actual expertise.
Every author on your site needs a dedicated entity profile. That means an author page with full credentials, publication history, external verification links, and structured Person markup. The days of generic staff bylines are over. If you can’t attribute content to a verifiable person, don’t publish it.
External verification is the constraint most teams ignore. You need sameAs links to: verified LinkedIn profile, institutional email domain, professional directory, and ideally either a Wikipedia page or a mention in a Wikipedia article. One link isn’t enough. The system cross-references multiple sources to confirm identity.
For Your Money or Your Life topics, author verification requirements are stricter. Medical content needs authors with MD credentials verifiable through state medical boards or hospital directories. Financial content needs CFP, CFA, or equivalent certifications confirmed through licensing databases. Self-reported credentials don’t count.
If you don’t have authors who meet these requirements, you have three options: hire credentialed experts, partner with verified subject matter experts, or exit high-expertise topics entirely. In practice, verification functions as a hard gate for most YMYL queries. Content quality alone rarely overcomes missing author verification.
Topic Cluster Architecture That Maps to Knowledge Graphs
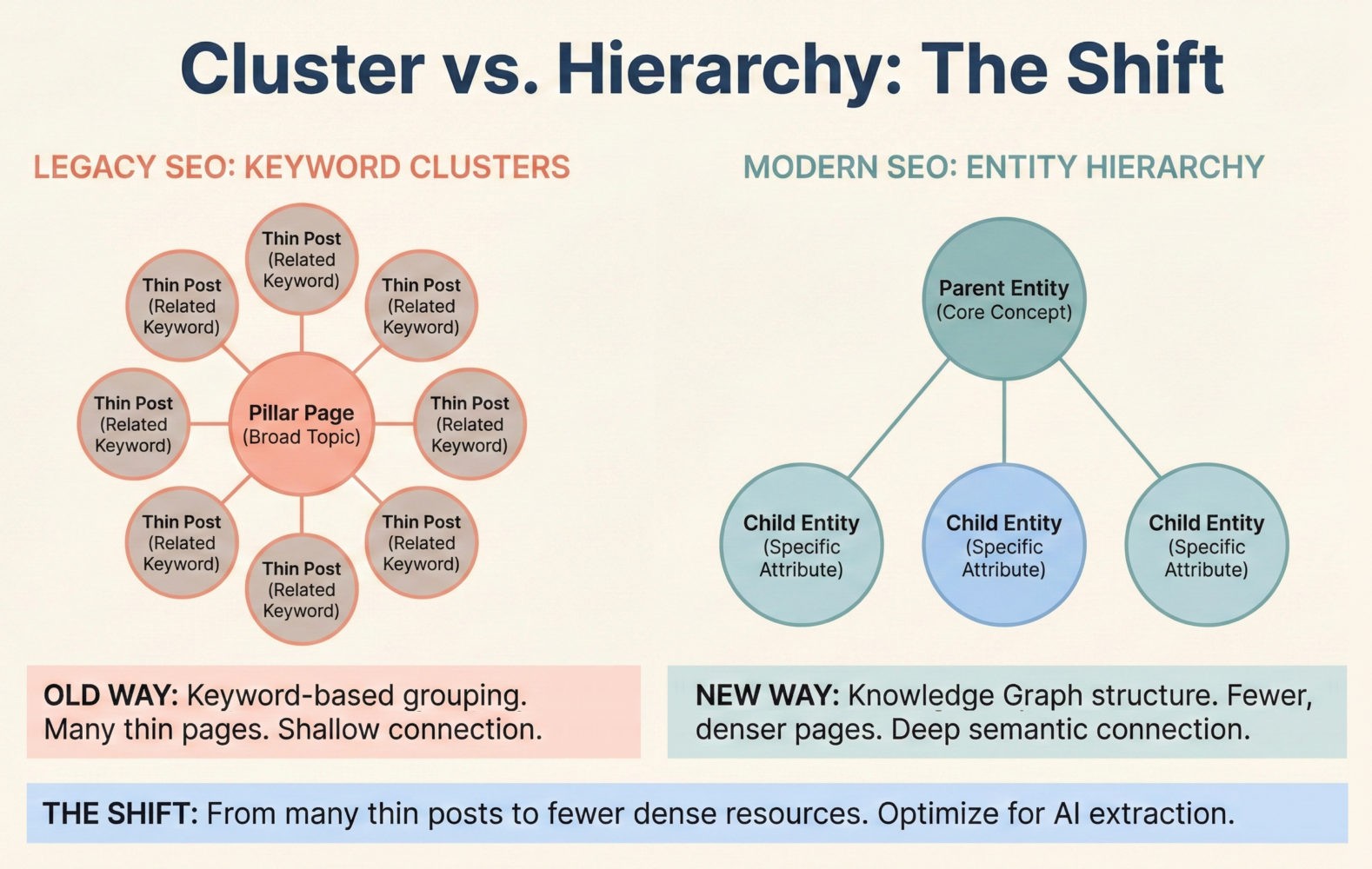
Effective topic clusters mirror Knowledge Graph entity hierarchies rather than keyword groupings. Instead of organizing content by search volume, structure it by entity relationships: parent/child classes, part/whole relationships, and causal dependencies.
Traditional topic clusters group content by keyword similarity. You create a pillar page for “content marketing” and cluster pages for “content strategy,” “content distribution,” “content measurement.” That makes sense from a keyword perspective. It doesn’t map to entity structures.
Knowledge Graphs organize information by entity type and relationship. Content Marketing (concept) contains Content Strategy (method), Content Distribution (process), Content Measurement (metric). Those aren’t separate clusters, they’re attributes of the parent entity.
The restructuring means fewer, denser pages instead of distributed content. One comprehensive resource on Content Marketing that defines strategy, distribution, and measurement as subsections gets extracted more reliably than four separate articles that each assume context from the others.
Internal linking patterns need to match entity relationships. Link from child entities to parent entities (specific to general), not sideways between sibling topics. The system interprets link direction as relationship assertion. Bidirectional links between peers create ambiguous hierarchy.
The Measurement Problem
Traditional SEO metrics (rankings, impressions, clicks) don’t fully measure AI Overview performance. Google Search Console still does not separate AI Overview traffic from traditional search. Clicks and impressions remain bundled in standard ‘Web’ reports, making performance tracking difficult..
You can rank #1 and receive zero AI Overview citations for the same query. Search Console shows the ranking. It doesn’t clearly separate whether Gemini extracted and cited your content. The two systems operate independently, and only one gets reliably tracked in standard analytics.
The workaround is manual extraction tracking. Search your target queries weekly and record which sources get cited in AI Overviews. Track citation frequency, position in the citation list, and whether you’re cited for primary or supporting facts. That data doesn’t exist in Search Console with sufficient granularity.
Traffic attribution breaks too. Users who read an AI Overview answer often don’t click through. If they do click, they skip directly to the cited section instead of landing on your page organically. Standard engagement metrics — time on page, bounce rate, conversion rate — become unreliable indicators of content quality.
The measurement gap forces a strategy decision: optimize for traditional rankings with trackable metrics, or optimize for AI citations with manual tracking overhead. Most teams can’t afford to do both well. You need to choose which system matters more for your business model and accept measurement limitations on the other.
Implementation Checklist for 2026
Adapting to entity-first search requires systematic content restructuring, author verification, and schema implementation. The following checklist prioritizes changes by impact, starting with the modifications that most directly affect extraction and citation rates.
High-Impact Actions
Audit existing content for entity clarity
Identify pages where primary entities aren’t explicitly named and categorized in the first paragraph. Rewrite openings to include the three-statement pattern: identification, categorization, differentiation.
Verify all author entities
Create dedicated author pages with Person schema, credentials, institutional affiliations, and external verification links. Remove generic bylines. If content can’t be attributed to a verifiable expert, either assign it to a qualified author or unpublish it.
Implement specific schema types
Replace generic Article markup with Product, HowTo, FAQPage, or other entity-specific types. Add sameAs links to external databases. Ensure schema attributes match what’s stated in body content—inconsistency triggers extraction failures.
Consolidate topic clusters
Merge thin supporting content into comprehensive parent resources. Reduce total page count while increasing entity density per page. Use redirect chains to preserve any existing authority, but don’t expect authority transfer—the extraction layer evaluates the new page independently.
Set up manual citation tracking
Create a monitoring schedule for target queries. Record AI Overview citations weekly. Track which competitors get cited and why. Use that data to identify extraction gaps in your own content.
Test entity extraction manually
Use Google’s Rich Results Test on your schema. Check whether entity attributes parse correctly. Run sample queries through Gemini and examine which facts get extracted. If your core claims aren’t being pulled, revise for explicitness.
Accept the traffic tradeoff
Entity-first content often reads more mechanically than traditional SEO content. The explicit declarations and repeated entity naming that help extraction can feel redundant to human readers. You’re optimizing for machines first. That’s the cost of AI visibility.
What This Means Operationally
The split between traditional ranking and AI extraction isn’t temporary. These are two parallel systems with different evaluation criteria. Content that wins in one doesn’t automatically win in the other. Your strategy needs to account for which system drives more value for your business.
If you depend on long-tail traffic and informational queries, AI Overviews are eliminating your distribution model. Users get answers without clicking. The pages that ranked #3-10 and generated 30% of your clicks now generate close to zero. That traffic isn’t coming back.
If you compete in high-expertise verticals (medical, legal, financial) author verification requirements will filter you out unless you employ credentialed experts. Content quality doesn’t override verification requirements. The system needs proof of credentials, not just well-written explanations.
The teams that adapt fastest are the ones willing to abandon legacy content structures. They’re consolidating thin blog posts into dense resources. They’re replacing marketing-approved author bios with verified expert profiles. They’re rewriting for entity extraction even when it makes the content less engaging for humans.
That’s the actual choice: continue optimizing for a ranking system that’s losing influence, or restructure for an extraction system that doesn’t care about your backlink profile. There’s no middle path that lets you win in both without significant resource allocation. Most teams will need to choose.





